


TABLE OF CONTENTS

Have questions or want a demo?
Introduction
PostgreSQL, a powerful open-source relational database management system, has long been revered for its robustness, extensibility, and SQL compliance. However, in recent times, there has been a paradigm shift in the way databases are utilized, with an increasing focus on vector data processing. This has led to the emergence of PostgreSQL as a formidable player in the realm of vector databases, further strengthened by the innovative pgvector extension.
pgvector is a PostgreSQL extension that provides powerful functionalities for working with vectors in a high-dimensional space. It introduces a dedicated data type, operators, and functions that enable efficient storage, manipulation, and analysis of vector data directly within the PostgreSQL database.
Tessell for PostgreSQL supports pgvector as a first-class integration
At Tessell, like any other company, we have generated a considerable amount of content in various forms, such as blogs, technical documents, FAQs, etc. Some are present publicly on our website, some on internal confluence and cloud drives, and with that comes the problem of too much information. Anyone new needs to scan through this abundance of information to figure things out.
So, we at Tessell thought, why not eat our own food first and decided to come up with an internal ChatGPT tool for our Sales and marketing teams to consume content in a Q&A fashion. This has helped our Sales, Sales Engineering, and Marketing teams to churn out content much more quickly.
So how did we go about doing it? This article talks about the step-by-step guide to building our own GPT.
Design
With the task cut out, we started to design the architecture of what the app would look like.
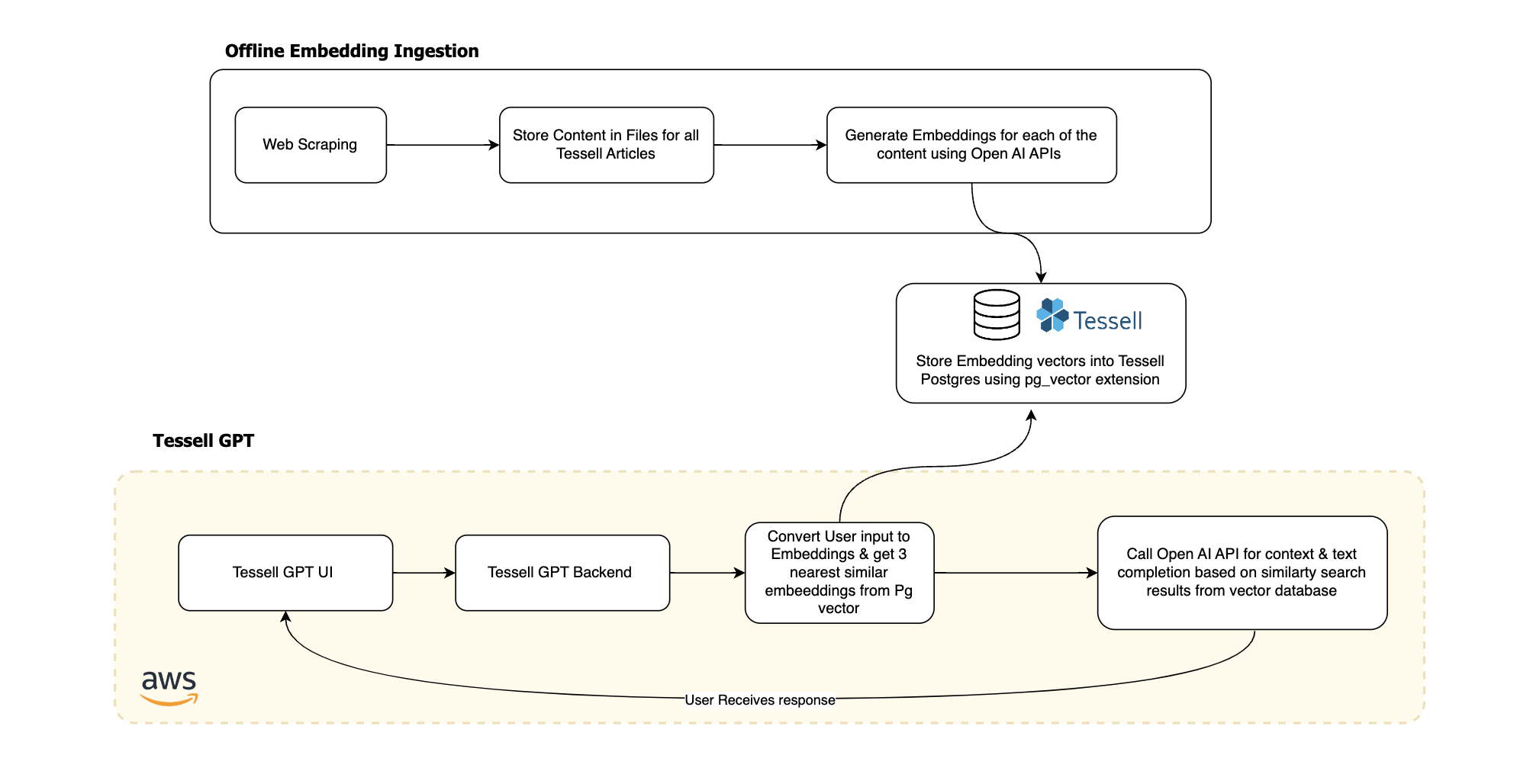
Tessell GPT consists of three major parts:
- Generate Vector embeddings for Content using OpenAI APIs.
- Storing Vector embeddings in PostgreSQL with pgvector.
- Retrieve embeddings from vector database to augment LLM generation, the whole process is also known as RAG (Retrieval Augmented Generation)
Now, that we have the the basic components of the design laid out let's look at a few important terms in the context of LLM Apps.
How to Create and Store OpenAI Embeddings for Your Documents?
And maybe the prior question is Why to generate embeddings of your documents in the first place?
While GPT-3 and GPT-4 are trained on huge datasets which is publicly available they may be missing some information needed to give a good answer because that information was not in the dataset used to train the model (for example, the information is stored in private documents or only became available recently); RAG addresses the problem that a foundational model may be missing data to give a correct precise answer.
RAG’s solution is dead simple: provide additional context to the foundational model in the prompt. For example, if someone asks GPT, “What is a Tessell DBaaS?” and the foundational model has never heard of Tessell, you can transform the prompt into context: “Tessell DBaaS is a cloud-based platform that simplifies the setup, management, security, and scalability of relational databases such as PostgreSQL, MySQL, Oracle, and Microsoft SQL Server. It also offers a managed service for event processing systems like Kafka. Tessell aims to be the go-to DBaaS platform for startups and enterprises by combining the benefits of cloud elasticity, utility economics, and enterprise-level governance and security.”
The foundational model can then use its knowledge of Tessell DBaaS to wax eloquently about Tessell. This technique is insanely powerful—it allows you to “teach” foundational models about things only you know about and use that to create a ChatGPT++ experience for your users.
But what context do you provide to the model? If you have a library of information, how do you know what’s relevant to a given question? Cue in embeddings. As mentioned above, OpenAI embeddings are a mathematical representation of the semantic meaning of a piece of text that allows for similarity search.
This means that if you get a user question and calculate its embedding, you can use a similarity search against data embeddings in your library to find the most relevant information. But that requires having an embedding representation of your library. Now this is where PostgreSQL as a vector database (with PgVector) forms the foundation of storing these embeddings.
So with basics out of the way, Let's get moving!
Setup
Set up your Virtual Python environment and install the following requirements.
You’ll need to sign up for an OpenAI Developer Account and create an OpenAI API Key – we recommend getting a paid account to avoid rate limiting and setting a spending cap so that you avoid any surprises with bills.
Once you have an OpenAI API key, it’s a best practice to store it as an environment variable and then have your Python program read it.
Generate Vector embeddings for Content using OpenAI APIs
Embeddings measure how related text strings are. First, we'll create embeddings using the OpenAI API on some text we want the LLM to answer questions on.
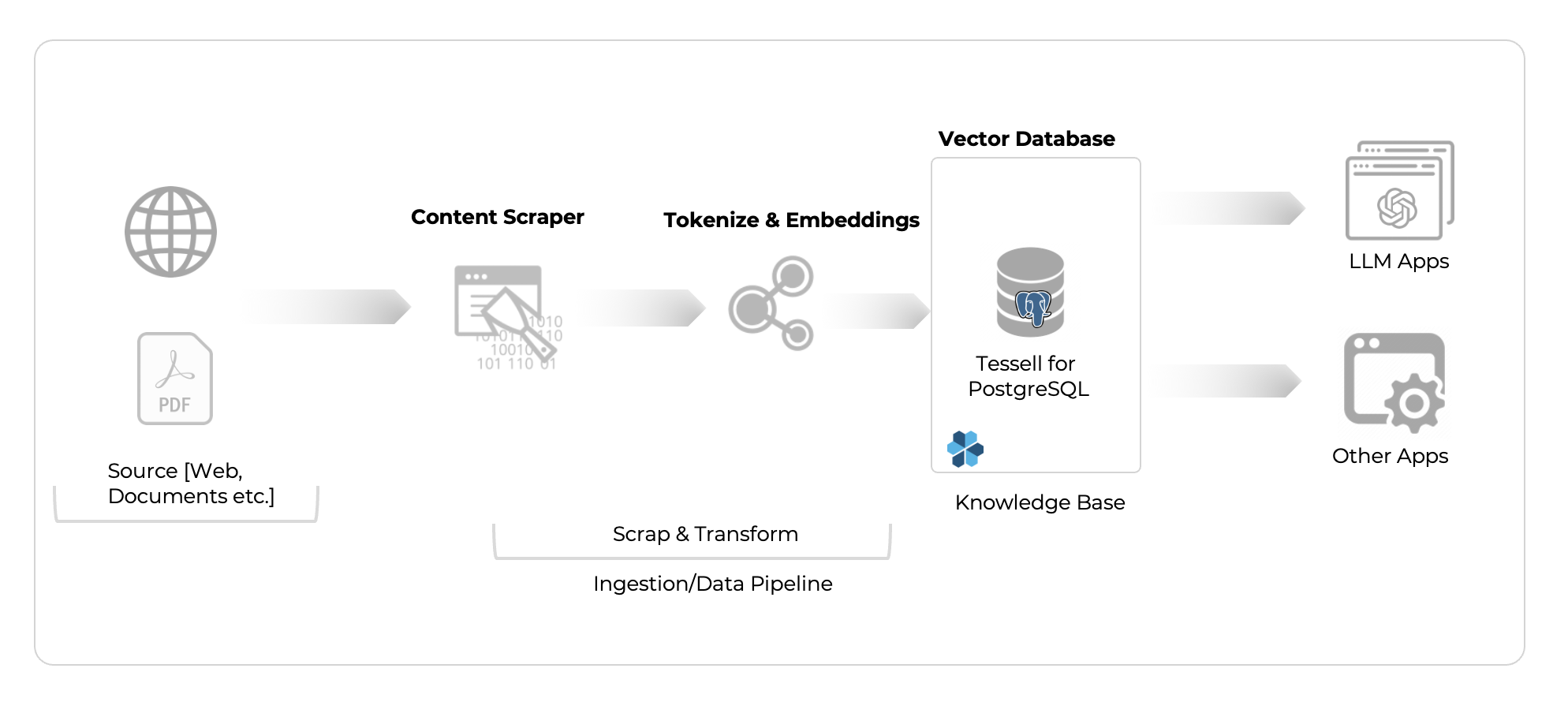
We first wanted to scrape all the public blogs, articles, and FAQs from tessell.com. This works as a good starting point for us to build our own LLM app.
There are various ways in which one can web scrape the data using various basic Python packages like BeautifulSoup or more specific LLM frameworks like Langchain & Llmaindex. We wrote our own content scraper using BeautifulSoup as we want to bring first-class ingestion interfaces to Tessell for our customers in the near future.
The scraped data was then stored in CSV files for further operation.
The output looks like this:
Once the content was available we tokenized the information and generated embeddings using OpenAI APIs
The new data frame with embeddings should look like this:
Storing Vector embeddings in PostgreSQL with pgvector
Now that we have created embedding vectors for our blog content, the next step is to store the embedding vectors in a vector database to help us perform a fast search over many vectors.
We’ll use PostgreSQL with the pgvector extension installed as our vector database. pgvector extends PostgreSQL to handle vector data types and vector similarity search, like nearest neighbor search, which we’ll use to find the k most related embeddings in our database for a given user prompt.
Create a Tessell for PostgreSQL database and install pgvector
First, we’ll create a PostgreSQL database. You can create a Tessell for PostgreSQL database in minutes for free on AWS or Azure or use a local PostgreSQL database for this step.
Once you’ve created your PostgreSQL database, export your connection string as an environment variable, and just like the OpenAI API key, we’ll read it into our Python program from the environment file:
We then connect to our database using the popular psycopg2 python library and install the pgvector extension as follows:
Connect to and configure your vector database
Once we’ve installed pgvector, we use the register_vector() command to register the vector type with our connection:
Once we’ve connected to the database, let’s create a table that we’ll use to store embeddings along with metadata. Our table will look as follows:
- id represents the unique ID of each vector embedding in the table.
- title is the blog title from which the content associated with the embedding is taken.
- url is the blog URL from which the content associated with the embedding is taken.
- content is the actual blog content associated with the embedding.
- tokens is the number of tokens the embedding represents.
- embedding is the vector representation of the content.
One advantage of using PostgreSQL as a vector database is that you can easily store metadata and embedding vectors in the same database, which is helpful for supplying the user-relevant information related to the response they receive, like links to read more or specific parts of a blog post that are relevant to them.
Ingest and store vector data into PostgreSQL using pgvector
Now that we’ve created the database and created the table to store the embeddings and metadata, the final step is to insert the embedding vectors into the database.
For this step, it’s a best practice to batch insert the embeddings rather than insert them one by one. Load the data frame that was generated in the first step.
Nearest Neighbor Search Using pgvector for RAG
Given a user question, we’ll perform the following steps to use information stored in the vector database to answer their question using Retrieval Augmented Generation:
- Create an embedding vector for the user question.
- Use pgvector to perform a vector similarity search and retrieve the k nearest neighbors to the question embedding from our embedding vectors representing the blog content. In our example, we’ll use k=3, finding the three most similar embedding vectors and associated content.
- Supply the content retrieved from the database as additional context to the model and ask it to perform a completion task to answer the user question.
Here’s the function we use to find the three nearest neighbors to the user question. Note it uses pgvector’s <=> operator, which finds the Cosine distance (also known as Cosine similarity) between two embedding vectors.
We supply helper functions to create an embedding for the user question and to get a completion response from an OpenAI model. We use GPT-3.5, but you can use GPT-4 or any other model from OpenAI.
We also specify a number of parameters, such as limits of the maximum number of tokens in the model response and model temperature, which controls the randomness of the model, which you can modify to your liking:
Alright, so now we have all the pieces of puzzle. Let's put them together
We’ll define a function to process the user input by retrieving the most similar documents from our database and passing the user input, along with the relevant retrieved-context to the OpenAI model to provide a completion response to.
Note that we modify the system prompt as well in order to influence the tone of the model’s response.
We pass to the model the content associated with the three most similar embeddings to the user input using the assistant role. You can also append the additional context to the user message.
This whole code was then packaged as a REST API and deployed on AWS and forms the backend of Tessell GPT
We also developed a static HTML/JS-based interface to interact with the application just like we do with ChatGPT.
This is how it looks:
Let's start with an easy one.
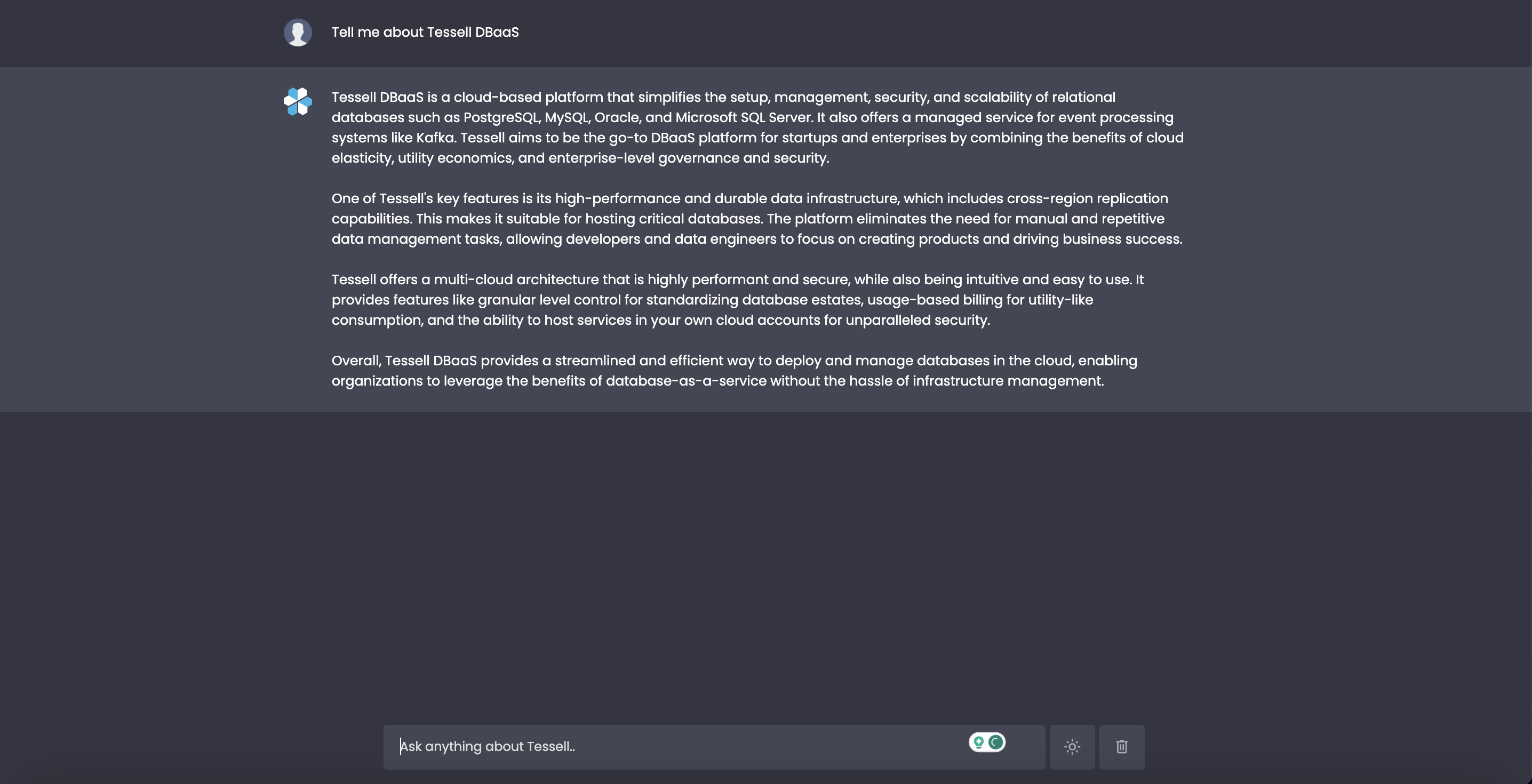
Let’s make it more specific.
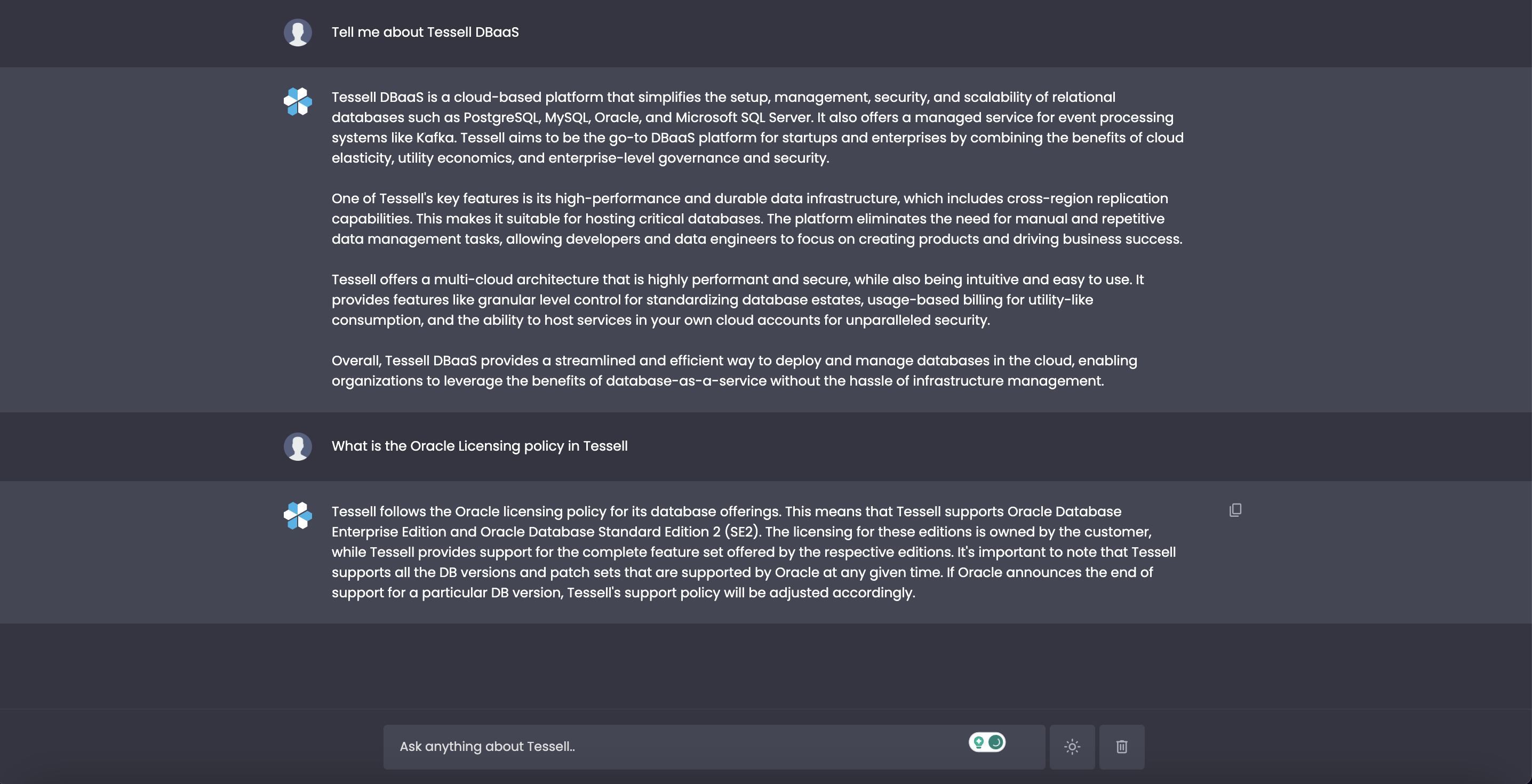
We often get asked about certain technical features of the product from customers, while the information is available in long-form documentation which often takes time to read and summarize. Let’s see what Tessell GPT does with one of such question.
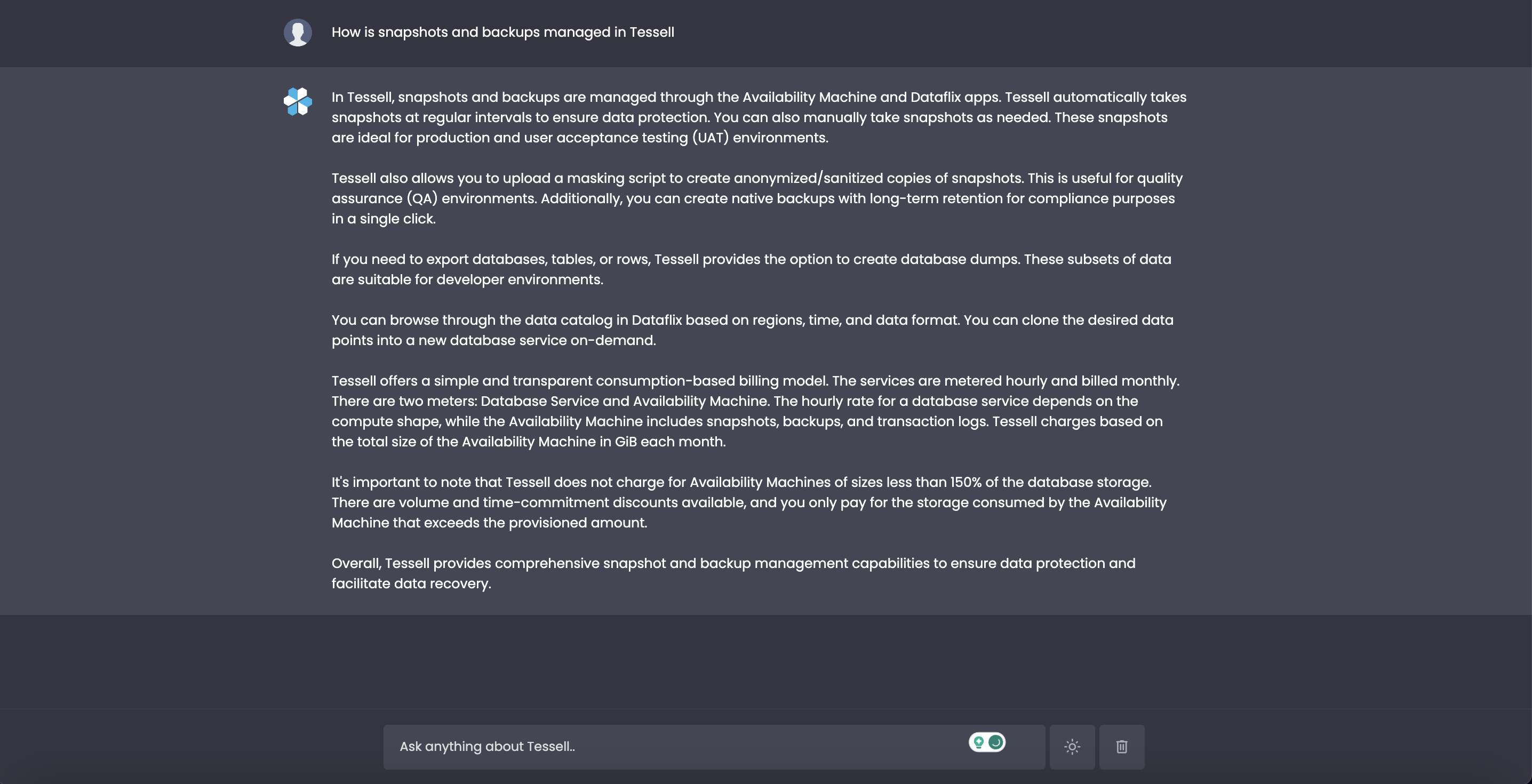
Pretty impressive..!
Conclusion
Retrieval Augmented Generation (RAG) is a powerful method of building applications with LLMs that enable you to teach foundation models about things it was not originally trained on—like private documents or recently published information.
We covered how we created Tessell GPT to answer questions about Tessell DBaaS. We used the content from the Tessell website, internal documents, etc. to show how to create, store, and perform similarity search on OpenAI embeddings. We used Tessell for PostgreSQL and pgvector as our vector database to store and query the embeddings.
And if you’re looking for a production PostgreSQL database for your vector workloads, try Tessell for PostgreSQL.
.webp)




